Pipelining for 3-6x Faster Commits
I’ve known about Postgres’s pipeline mode for a while, and finally have some prototyping of pipelining in general, and alpha builds of Joist running with pipeline mode (coming soon!).
This post is an intro to pipelining, using postgres.js and mitata to benchmark some examples.
What is Pipelining?
Section titled “What is Pipelining?”Pipelining, as a term in networking, allows clients to send multiple requests, immediately one after each other, without first waiting for the server to respond.
Without Pipelining
Section titled “Without Pipelining”Using NodeJS talking to Postgres for illustration, the default flow of SQL statements, without pipelining, involves a full round-trip network request for each SQL statement:
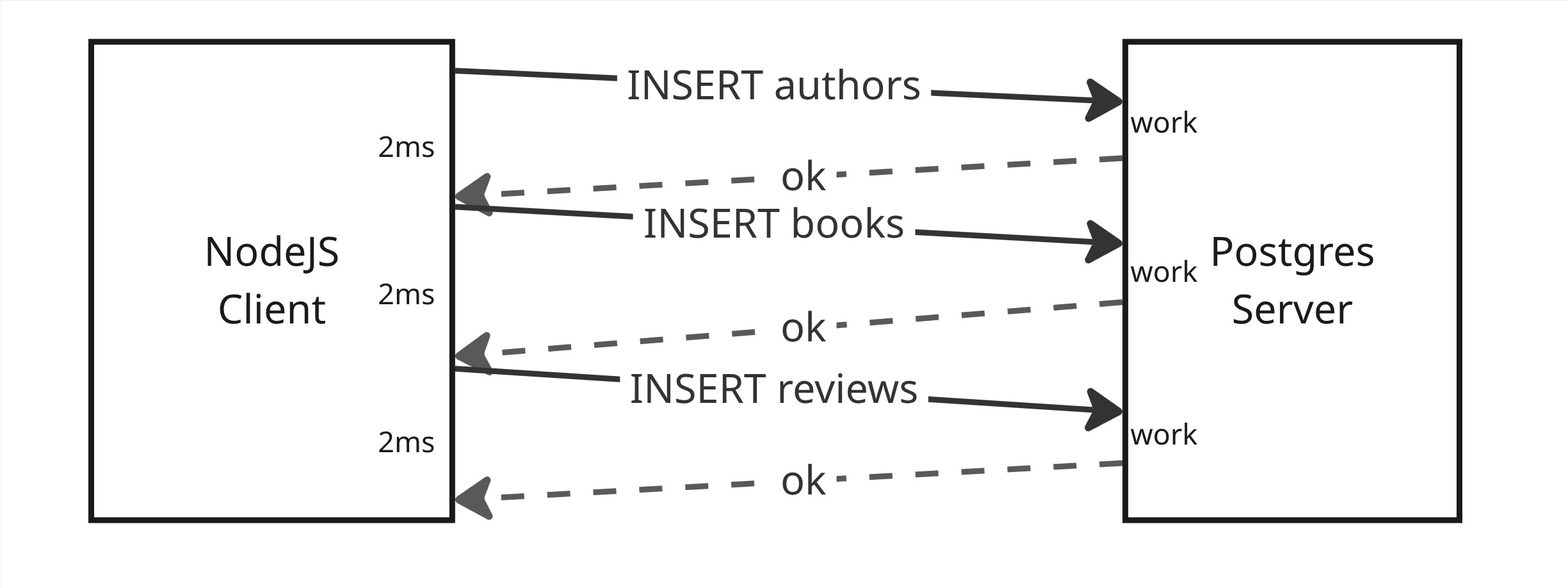
- Send an
INSERT authors - …wait several millis for work & response…
- Send an
INSERT books - …wait several millis for work & response…
- Send an
INSERT reviews - …wait several millis for work & response…
Note that we have to wait for both:
- The server to “complete the work” (maybe 1ms), and
- The network to deliver the responses back to us (maybe 2ms)
Before we can continue sending the next request.
This results in a lot of “wait time”, for both the client & server, while each is waiting for the network call of the other to transfer over the wire.
With Pipelining
Section titled “With Pipelining”Pipelining allows us to remove this “extra wait time” by sending all the requests at once, and then waiting for all responses:
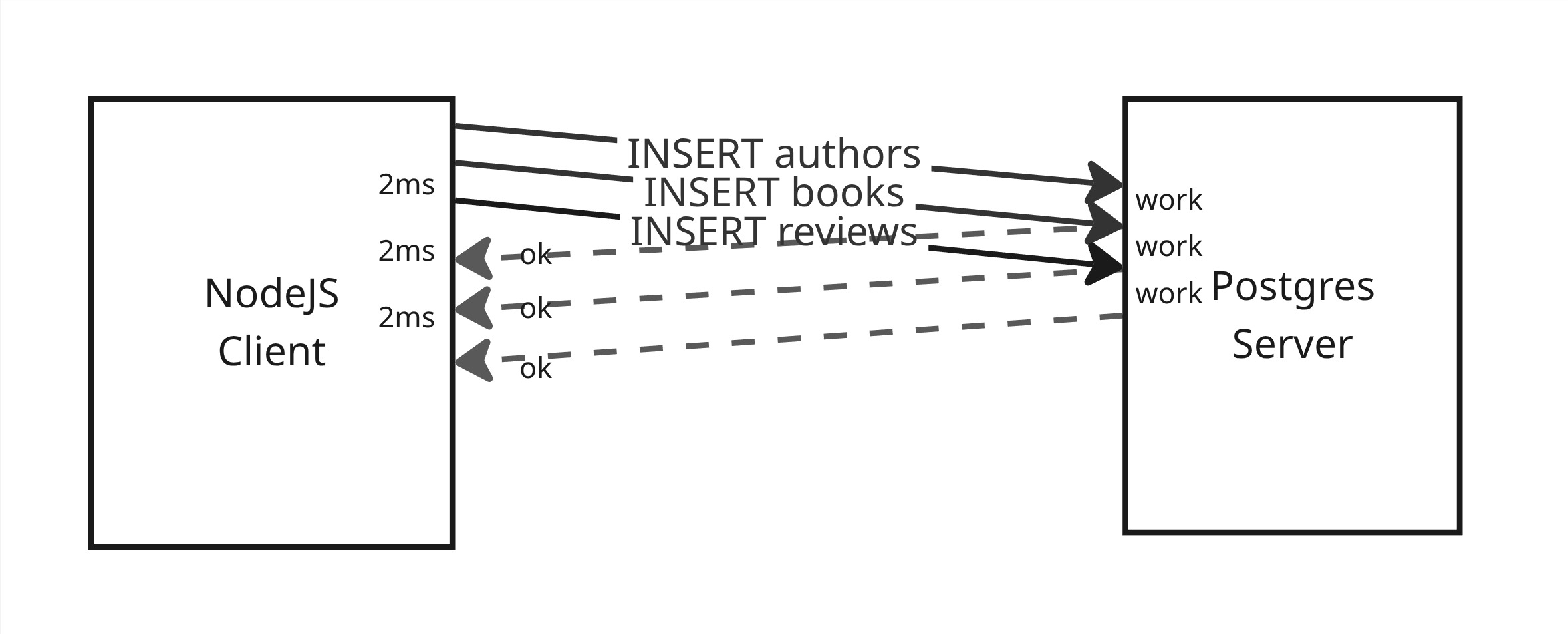
- Send
INSERT authors - Send
INSERT books - Send
INSERT reviews - …wait several millis for all 3 requests to complete…
The upshot is that we’re not waiting on the network before sending the server more work to do.
Not only does this let our client “send work” sooner, but it lets the server have “work to do” sooner as well—i.e. as soon as the server finishes INSERT authors, it can immediately start working on INSERT books.
Transactions Required
Section titled “Transactions Required”One wrinkle with pipelining is that if 1 SQL statement fails (i.e. the INSERT authors statement), all requests that follow it in the pipeline are also aborted.
This is because Postgres assumes the later statements in the pipeline relied on the earlier statements succeeding, so once earlier statements fail, the later statements are considered no longer valid.
This generally means pipelining is only useful when executing multi-statement database transactions, where you’re executing a BEGIN + some number of INSERT, UPDATE, and DELETE statements + COMMIT, and we already expect them to all atomically commit.
Serendipitously, this model of “this group of statements all need to work or abort” is exactly what we want anyway for a single backend request that is committing its work, by atomically saving its work to the database in a transaction—and is exactly what Joist’s em.flush does. :-)
Benchmarking Wire Latency
Section titled “Benchmarking Wire Latency”Per above, network latency between your machine & the database is the biggest factor in pipelining’s performance impact.
This can make benchmarking difficult and potentially misleading, because benchmarks often have the “web backend” and “the database” on the same physical machine, which means there is effectively zero network latency.
Thankfully, we can use solutions like Shopify’s toxiproxy to introduce an artificial, deterministic amount of latency to the network requests between our Node process and the Postgres database.
toxiproxy is particularly neat in that it’s easy to run as a docker container, and control the latency via POST commands to a minimal REST API it exposes:
services: toxiproxy: image: ghcr.io/shopify/toxiproxy:2.12.0 depends_on: db: condition: service_healthy ports: - "5432:5432" - "8474:8474" volumes: - ./toxiproxy.json:/config/toxiproxy.json command: "-host=0.0.0.0 -config=/config/toxiproxy.json"[ { "name": "postgres", "listen": "0.0.0.0:5432", "upstream": "db:5432", "enabled": true }]curl -X POST http://localhost:8474/resetcurl -X POST http://localhost:8474/proxies/postgres/toxics -d '{ "name": "latency_downstream", "type": "latency", "stream": "downstream", "attributes": { "latency": 2 }}'Is all we need to control exactly how much latency toxiproxy injects between every Node.js database call & our docker-hosted postgres instance.
Leveraging postgres.js
Section titled “Leveraging postgres.js”We’ll look at Joist’s pipeline performance in a future post, but for now we’ll stay closer to the metal and use postgres.js to directly execute SQL statements in a few benchmarks.
We’re using postgres.js instead of the venerable node-pg solely because postgres.js implements pipelining, but node-pg does not yet.
postgres.js also has an extremely seamless way to use pipelining—any statements issued in parallel (i.e. a Promise.all) within a sql.begin are automatically pipelined for us.
Very neat!
Benchmarks
Section titled “Benchmarks”0. Setup
Section titled “0. Setup”We’ll use mitata for timing info—it is technically focused on CPU micro-benchmarks, but its warmup & other infra make it suitable to our async, I/O oriented benchmark as well.
For SQL statements, we’ll test inserting tag rows into a single-column table—for these tests, the complexity/cost of the statement itself is not that important, and a simple insert will do.
We have a few configuration parameters, that can be tweaked across runs:
numStatementsthe number of tags to inserttoxiLatencyInMillisthe latency in millis that toxiproxy should delay each statement
As we’ll see, both of these affect the results—the higher each becomes (the more statements, or the more latency), the more performance benefits we get from pipelining.
1. Sequential Inserts
Section titled “1. Sequential Inserts”As a baseline benchmark, we execute numStatements inserts sequentially, with individual awaits on each INSERT:
bench("sequential", async () => { await sql.begin(async (sql) => { for (let i = 0; i < numStatements; i++) { await sql`INSERT INTO tag (name) VALUES (${`value-${nextTag++}`})`; } });});We expect this to be the slowest, because it is purposefully defeating pipelining by waiting for each INSERT to finish before executing the next one.
2. Pipelining with return value
Section titled “2. Pipelining with return value”This is postgres.js’s canonical way of invoking pipelining, returning a string[] of SQL statements from the sql.begin lambda:
bench("pipeline string[]", async () => { await sql.begin((sql) => { const statements = []; for (let i = 0; i < numStatements; i++) { statements.push(sql`INSERT INTO tag (name) VALUES (${`value-${nextTag++}`})`); } return statements; });});We expect this to be fast, because of pipelining.
3. Pipelining with Promise.all
Section titled “3. Pipelining with Promise.all”This last example also uses postgres.js’s pipelining, but by invoking the statements from within a Promise.all:
bench("pipeline Promise.all", async () => { await sql.begin(async (sql) => { const statements = []; for (let i = 0; i < numStatements; i++) { statements.push(sql`INSERT INTO tag (name) VALUES (${`value-${nextTag++}`})`); } await Promise.all(statements); });});This is particularly important for Joist, because even within a single em.flush() call, we’ll execute a single BEGIN/COMMIT database transaction, but potentially might have to make several “waves” of SQL updates (technically only when ReactiveQueryFields are involved), and so can’t always return a single string[] of SQL statements to execute.
We expect this to be fast as well.
Performance Results
Section titled “Performance Results”I’ve run the benchmark with a series of latencies & statements.
1ms latency, 10 statements:
toxiproxy configured with 1ms latencynumStatements 10clk: ~4.37 GHzcpu: Intel(R) Core(TM) i9-10885H CPU @ 2.40GHzruntime: node 23.10.0 (x64-linux)
benchmark avg (min … max)-------------------------------------------sequential 15.80 ms/iterpipeline string[] 4.16 ms/iterpipeline Promise.all 4.21 ms/iter
summary pipeline string[] 1.01x faster than pipeline Promise.all 3.8x faster than sequential1ms latency, 20 statements:
toxiproxy configured with 1ms latencynumStatements 20clk: ~4.52 GHzcpu: Intel(R) Core(TM) i9-10885H CPU @ 2.40GHzruntime: node 23.10.0 (x64-linux)
benchmark avg (min … max)-------------------------------------------sequential 30.43 ms/iterpipeline string[] 4.55 ms/iterpipeline Promise.all 4.51 ms/iter
summary pipeline Promise.all 1.01x faster than pipeline string[] 6.74x faster than sequential2ms latency, 10 statements:
toxiproxy configured with 2ms latencynumStatements 10clk: ~4.53 GHzcpu: Intel(R) Core(TM) i9-10885H CPU @ 2.40GHzruntime: node 23.10.0 (x64-linux)
benchmark avg (min … max)-------------------------------------------sequential 28.85 ms/iterpipeline string[] 7.27 ms/iterpipeline Promise.all 7.54 ms/iter
summary pipeline string[] 1.04x faster than pipeline Promise.all 3.97x faster than sequential2ms latency, 20 statements:
toxiproxy configured with 2ms latencynumStatements 20clk: ~4.48 GHzcpu: Intel(R) Core(TM) i9-10885H CPU @ 2.40GHzruntime: node 23.10.0 (x64-linux)
benchmark avg (min … max)-------------------------------------------sequential 55.05 ms/iterpipeline string[] 9.17 ms/iterpipeline Promise.all 10.13 ms/iter
summary pipeline string[] 1.1x faster than pipeline Promise.all 6x faster than sequentialSo, in these benchmarks, pipelining makes our inserts (and ideally future Joist em.flush calls!) 3x to 6x faster.
A few notes on these numbers:
-
1-2ms latency I think is a generally correct/generous latency, based on what our production app sees between an Amazon ECS container and RDS Aurora instance.
(Although if you’re using edge-based compute this can be as high as 200ms :-O)
-
10 statements per
em.flushseems like a lot, but if you think about “each table that is touched”, whether due to anINSERTorUPDATEorDELETE, and include many-to-many tables, I think it’s reasonable for 10-tables to be a not-uncommon number.Note that we assume your SQL statements are already batched-per-table, i.e. if you have 10 author rows to
UPDATE, you should be issuing a singleUPDATE authorsthat batch-updates all 10 rows. If you’re using Joist, it already does this for you.
Pipelining FTW
Section titled “Pipelining FTW”I created this raw SQL benchmark to better understand pipelining’s l-wlevel performance impact, and I think it’s an obvious win: 3-6x speedups in multi-statement transactions.
As a reminder/summary, to leverage pipelining you need three things:
- A postgresql driver that supports it,
- Be executing multi-statement transactions, and
- Structure your code such that all the transaction statements are submitted in parallel
This last one is where Joist is the most helpful—it’s em.flush() method automatically generates the INSERTs, UPDATEs, and DELETEs for your changes, and so it can automatically submit them using a Promise.all, and not require any restructuring in your code.
In a future/next post, we’ll swap these raw SQL benchmarks out for higher-level ORM benchmarks, to see pipelining’s impact in more realistic scenarios.